
As I’ve said before, I wish my library had the funds for a coding wizard who was given time to work on new projects to enhance our library systems,Grow your own OPAC…but save those kittens. I think a position like this would be useful to:
- get our systems talking better to each other
- reduce the number of places our clients need to go, or steps they need to do, on our websites.
- advise us of cheaper, easier, software or enhancements to current software.
- Show librarians like electronic services librarians, web librarians, emerging technology librarians and immersive technology librarians, how to do some of what we do better.
I also think that, like most libraries, we are stretched for funds and at this stage a library developer would be on a “dream on” list.
But….dreaming on…here’s an example of how just a couple of lines of javascript on the footer of a record display template can value add enormously. When I compare the cost to hire someone to do this, as opposed to the huge purchase costs of an off the shelf module, I begin to wonder about whether I should be quite so quick to dismiss a library developer as a luxury. (Lest I sound too optomistic, I do realise that their are issues like maintenance and LibraryThing’s business model to consider)
Danbury Library has added data from LibraryThing to its III catalogue, Danbury, CT kicks off LibraryThing for Libraries!
Their records now include a list of “other editions” plus “translations and similar books”. You can click on a tag and see what else in the library has the same tag. It harvests the data from LibraryThing – using information from thousands of LibraryThing users who have used it to catalogue their home collections in plain English, not from cataloguers.
In their record for Jane Eyre, (image below), the last three fields are generated from LibraryThing’s data.
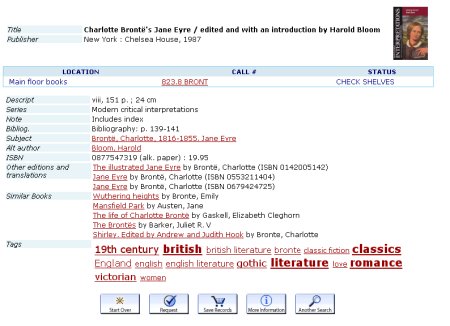
I tried it this morning and the tag browser was too slow to be useful, but the “other editions” and “similar books” looked fantastic.
It’s not perfect, it is developmental and it is FREE. Here’s some more information about the project from the Thingology post.
How it works. Perhaps the most remarkable thing here is the relative ease with which Danbury added the feature. Danbury has an Innovative Interfaces OPAC (“WebPac”), but LibraryThing for Libraries is platform agnositic. There is no back-end integration–no one at Danbury had to call their vendor. Ultimately, it involved just a few lines of JavaScript pasted into the page footer. It works on any modern browser. It causes your tea service to fill with magical gold. Okay, not that.
Caveats.
Some things we’re working on:
- So far, it only knows ISBN books.
- The Tag Browser is not fast enough. This can be improved, no question.
- There are some wrinkles in the tag data, particularly in marginal cases. Some of this will go away, but not all of it.
- There are some character problems, like the tag “C++” turning into “C.”
- In the rush to get the feature out, we forgot to give Danbury the “noscript” tag, so that users with JavaScript turned off can enjoy the enhanced content.
Improvements:
- We wanted to start with non-interactive features. We love user tagging, but wanted to show what out existing data could do without any additional patron data. There are also sticky privacy issues there. But, of course, this is a direction we’ll be moving in.
The Future. Getting one library out takes a lot of pressure off us. We’ve been doing a lot of custom work to show potential customers what we’re going to offer. With a major test case live, we can cut back on that. We’ve also learned a lot more about the problems of importing library data, and are making progress there. We’ll moving into “production” mode, and getting back to other libraries soon.